本文将列举开源的大语言模型模型和微调的类型,并以代码形式具体介绍如何进行微调。
为何选择微调
作为个人开发者,想要”私人定制“大语言模型(Large Language Model,LLM),乃至在垂直领域完成一个问答系统,或者至至至少,得要认主,在追问“你是谁”的时候,不会回答“我是由OpenAI开发的模型”,而回答的是”我是jin开发的聊天机器人”。对开源的LLM进行微调,是个不错的方案。
为什么不直接用ChatGPT?因为ChatGPT是一个闭源的产品,我们既无法在本地部署快速使用,也不确保其内部会不会泄露我的隐私数据。要采用这种方案,需要先科学上网,给OpenAI付钱,再输入垂直领域特定的提示词,最后输入自己的问题。比如对于科研论文总结,需要输入“你是一个优秀的博士生,阅读这篇论文后,写一篇笔记博客发到网上,请列出你的大纲,一节一节的写出笔记”的提示词,再输入论文原文。这个方案不仅速度更慢、隐私性差,而且ChatGPT可能无法专业地回答特定领域的问题。
最好针对垂直领域,从头训练一个LLM,但是这样的成本无疑是巨大的,不仅面临数据标注、算法设计、环境部署等问题,还缺乏硬件设备。据推算,训练一个标准大小的ChatGPT-175B,大概需要一千台左右8张80GB显存的A100服务器训练一个月,成本达上亿元人民币。类似大小的开源模型BLOOMChat-176B,半精度(fp16/bf16)推理同样需要8张A100(一张10多万,且对我们禁售)。
而微调则是在既有的LLM上,额外加入少量的参数进行控制,达到修改模型的目的。能够在低资源条件下,构建本地的垂直领域LLM,如医疗领域的Huatuo,法律领域的LaWGPT等,还可以对不同任务训练不同的额外参数,使用相同的LLM+不同的控制,应对不同的下游场景。
开源LLM
目前可以直接下载的开源LLM如下表(点击模型名直达链接):
| 模型名 | 机构 | 基底 | 大小(B) |
|---|---|---|---|
| ChatGLM-6B | 清华THUDM | GLM | 6 |
| MOSS-SFT | 复旦NLP | MOSS | 16 |
| BLOOMZ | BigScience | BLOOM | 0.56-176 |
| ChatPLUG | 阿里达摩院 | PLUG | 3 |
| GPT-J | EleutherAI | Mesh Transformer JAX | 6 |
| LLaMA | Meta AI | - | 7-64 |
| Flan-T5 | T5 | 3-11 | |
| Stable-vicuna | CarperAI | vicuna | 13 |
| CPM-Bee和CPM-Ant | OpenBMB | - | 1-10 |
| OPD和CDial-GPT | 清华coai | - | 6.3 |
| RWKV | BlinkDL | - | 0.169-14 |
基底指该模型没有在对话任务上进行调整的源模型,中间有-的表示模型大小范围,算力不够可以选择小模型。此外还有纯基底的模型如IDEA的封神系列、华为盘古的PanGu、清华的CPM等。还有基于上表的模型再继续微调,取得较好效果的模型,如基于BLOOMZ的Phoenix、基于LLaMA的Chinese-LLaMA-Alpaca、基于GPT-J的Dolly等。在huggingface和其LLM排行榜中可以查看更多,在使用时请遵循各个模型的协议。
微调的类型和简介
拥有垂直领域的数据,就可以对开源LLM进行该领域微调。但首先需要厘清一个概念:在LLM之前,微调基本就专指Finetune(详见前文)。Finetune需要对模型结构加以修改,例如对于BERT这类预训练模型,要做文本分类任务,需要在其最后层再多接一个分类层。而LLM将所有任务统一成了问答形式,不再改变LLM的输入输出形式,下文探讨的都是这种形式的微调。
本文探讨的微调LLM无需针对不同任务改变模型的内部结构,即原本的LLM参数是冻结的,仅仅加入一些额外的控制参数。目前主要有Prompting和LoRA两种形式,Prompting是以增加embedding的形式达到控制,LoRA则改变了模型的权重。
Prompting
Prompting的方法分为hard prompts和soft prompts:
- Hard prompts指人工设计提示模板输入,也就是上文提到的输入提示词的方法,但是这种方法需要花费大量人力去设计提示词模板;
- Soft prompts指把提示设计成可学习的张量,可以根据数据更新自己,但这个张量是不可读的,因为没有对应到具体的token。
Hard prompts是离散的一个个词,而soft prompts本质上是连续的,能够达到最优化,实验普遍证明soft的效果更好。下面的prompting方法都是soft prompts:
- Prompt tuning,针对T5的分类任务设计。Prompt tuning在每个句子前拼上类似embedding的可学习张量,不同任务分别设置各自的张量,再输入LLM。训练时冻结LLM参数,只更新可学习的这个张量。
- Prefix tuning,针对GPT的自然语言生成(NLG)任务设计。Prefix tuning和Prompt tuning的直接区别在于prefix的参数加到了LLM的所有层中。训练时冻结LLM参数,prefix不仅经过LLM,也得过单独的FFN进行稳定性和性能的优化,这个FFN训练完后就被抛弃了,只保留prefix张量。
- P-tuning,这个方法的论文题目就很炸裂《GPT Understands, Too》,侧重所有模型的自然语言理解(NLU)而设计。P-tuning类似Prompt tuning在句子输入前拼可学习张量,区别在于这个张量经过了LSTM等相对小的模型预先处理。训练时冻结LLM参数,更新这个LSTM网络和可学习张量。实验证明P-tuning效率更高,并且使得GPT也具备了BERT类模型的理解能力。
- P-tuning v2,结合了前两者,P-tuning得到的张量以Prefix的形式拼到每一层。
值得一提的是,Prompt在训练和推理时是两码事,训练的Prompt指以上这些方法,而推理时的Prompt指给模型输入的文本。我们平常看到的“提示词工程师”,是在推理上,通过调整Prompt获得LLM更好的返回结果,而并非设计训练方法的,而随着各种提示词网站的兴起和AI理解能力的提高,个人认为这一职业注定昙花一现。
LoRA
LORA(LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)本质上是个adapter,以往的adapter在模型的层间加入降维-激活-升维的层,并在训练时只更新这一部分,比如在原始的transformer多头注意力或FFN后添加adapter。显然,adapter会在模型中添加额外的层,这些层会导致大模型在推理时需要更多的GPU资源,而且也会约束模型并行。这些问题都将导致模型推理变慢。LoRA对此进行改进,如图:
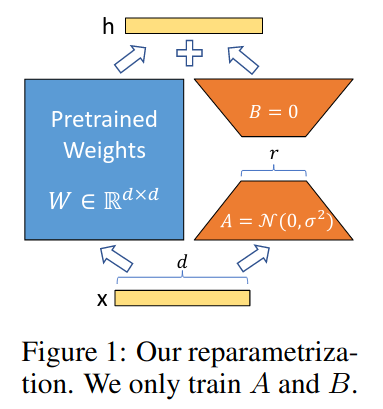
LoRA认为神经网络的权重矩阵可以分解成更低秩的矩阵,因此在训练时,不用直接计算整个权重矩阵的梯度\(\Delta W\),只需将其分解成两个小矩阵\(B\)和\(A\),再相乘即可,如下式: \(W_0 + \Delta W = W_0 + BA\) 对矩阵\(A\)使用随机高斯初始化,对矩阵\(B\)使用0进行初始化,随后根据梯度更新\(BA\),而模型的原始权重\(W_0\)不发生任何改变。当需要转换至另一个下游任务,可以通过减去\(BA\)来恢复\(W_0\),然后添加不同的\(B^{'}A^{'}\)。至关重要的是,这样的操作是并行的,不会造成推理变慢。
利用PEFT进行微调
接下来用代码简单呈现如何微调。HuggingFace提供了针对微调的库PEFT(Parameter-Efficient Fine-Tuning),支持LoRA、Prefix Tuning、P-Tuning、Prompt Tuning、AdaLoRA、LLaMA-Adapter等方法。下面的代码是用Prompt Tuning在twitter数据集上对bloomz-560m模型微调,相对资源要求较小,可以尝试下。
首先安装一些必要的库:
1
pip install transformers accelerate evaluate datasets loralib peft -q
初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from transformers import AutoModelForCausalLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
from peft import get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType
import torch
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
# 如果是LoRA就换成LoraConfig,Prefix tuning对应PrefixTuningConfig等
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
加载和处理数据
数据为csv文件,格式如下,可以将自己的数据处理成类似格式进行微调~
| Tweet text | Label | ID |
|---|---|---|
| @HMRCcustomers No this is my first job | no complaint | 0 |
1
2
3
4
5
6
7
8
9
10
11
12
13
# 定义标签的键名
label_column = "text_label"
# 加载ought/raft的twitter_complaints数据
dataset_name = "twitter_complaints"
dataset = load_dataset("ought/raft", dataset_name)
# 修改标签为["complaint", "no complaint", "Unlabeled"]
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
dataset = dataset.map(
lambda x: {label_column: [classes[label] for label in x["Label"]]},
batched=True,
# 进程数
num_proc=1,
)
加载原始数据后,将数据处理成模型的输入格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
def preprocess_function(examples):
max_length = 64
batch_size = len(examples[text_column])
text_column = "Tweet text"
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets)
# padding
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.pad_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# truncation
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
num_epochs = 50
batch_size = 8
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["train"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 加载原模型
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
# 加载Prompting模型
model = get_peft_model(model, peft_config)
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-2)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
# 保存模型到本地
checkpoint_name = "./output"
model.save_pretrained(checkpoint_name)
推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel, PeftConfig
import torch
device = "cuda"
model_name_or_path = "./bloomz-560m"
tokenizer_name_or_path = "./bloomz-560m"
checkpoint_name = "./output"
text_column ="Tweet text"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
config = PeftConfig.from_pretrained(checkpoint_name)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, checkpoint_name)
inputs = tokenizer(
f'{text_column} : {"@nationalgridus I have no water and the bill is current and paid. Can you do something about this?"} Label : ',
return_tensors="pt",
)
model.to(device)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))