RNNs模型,包括LSTM和GRU,是处理Seq2seq任务的经典模型。RNNs的代码非常适合深度学习入门,本文将介绍Seq2seq的基本概念,RNNs模型的原理和公式,最后以基于AKShare+LSTM股票市场预测为例,让读者通过实践彻底理解RNNs。
Seq2seq
序列到序列(Seq2seq)任务表示输入是一段序列,输出也是一段序列的任务。序列是被顺序排成一列的对象,文本、视频、语音、时序数据都可以视作序列。Seq2seq的任务在日常生活中都随处可见,例如文本翻译,输入”Jin is so handsome“输出”金是真的帅“;又如下文中的例子,通过前几日的交易数据预测下一日的涨跌。
Seq2seq的一种经典结构叫做Encoder-Decoder(编码-解码),来源于一个非常直观的感受:当人类阅读完一段文本后,会留下印象;当复述这段文本时,会根据印象,一个字一个字写出接下来的文本。留下印象的过程就是Encoder,根据印象逐字写下文就是Decoder。
注意,seq2seq是一种任务的形式,而我们常听到的RNN、LSTM、GRU,以及Attention、Transformers等是模型,都可以作为模拟seq2seq任务的工具。这些模型的Encoder-Decoder结构处理流程可以表示为:
- Input:输入一段长为$N$的序列$X={ x_0, x_1, …, x_N}$。
- Encoder:$h_t=Encoder(X)$。获得的隐藏状态$h_t$,也叫做context vector/上下文向量,也常表示为$z$,即$h_t=z$。可以视作包含了整个输入序列的信息。
- Decoder:$S=Decoder(z)$。解码得到的结果可以是序列,也可以是单条数据。
- Output:$Y=OutputLayer(S)$。由此得到最后的结果。
这些公式和部件的具体内容因模型而异,下面以LSTM为例详解序列数据的处理。
LSTM
细致和深入讲解LSTM的教程已有很多,本文只讲讲我的理解,并分享相关的代码。
RNN类模型的结构都可以表示为下图:
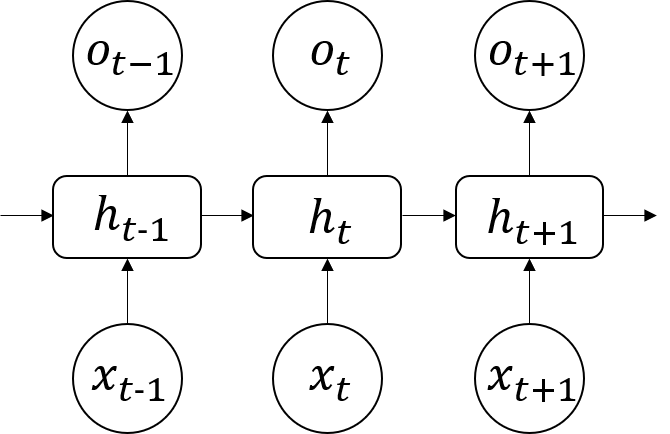
图中${ …,x_{t-1},x_{t},x_{t+1},…}$为输入的时序数据;${ …,h_{t-1},h_{t},h_{t+1},…}$表示隐藏状态,会被模型记录接着传下去,也可以通过输出层后作为输出${ …,o_{t-1},o_{t},o_{t+1},…}$。公式为:
\[h_t = \tanh(x_t W^T + h_{t-1} U^T)\]公式很好理解,这一时刻的状态由这一时刻的输入和上一时刻的状态两部分组成,并且各自乘上了权重。初学时比较困惑的点是:
- 每一时刻是什么意思?就是每次输入$x$的时候。
- $h$具体到底是什么?就是和$x$类似的向量。
- 最开始的$h$是哪来的?随机初始化的。
- 模型到底在学什么?学习的并不是$h$,而是权重,每刻都会循环更新权重,也就是其名字Recurrent的由来。
理解RNN后,LSTM的机制也能够轻松理解。由于RNN对隐藏状态的一股脑的加,很容易出现长期依赖问题:结果只和最近的输入有关,并且存在梯度消失和爆炸问题。于是有了LSTM作为解决方案,如图:
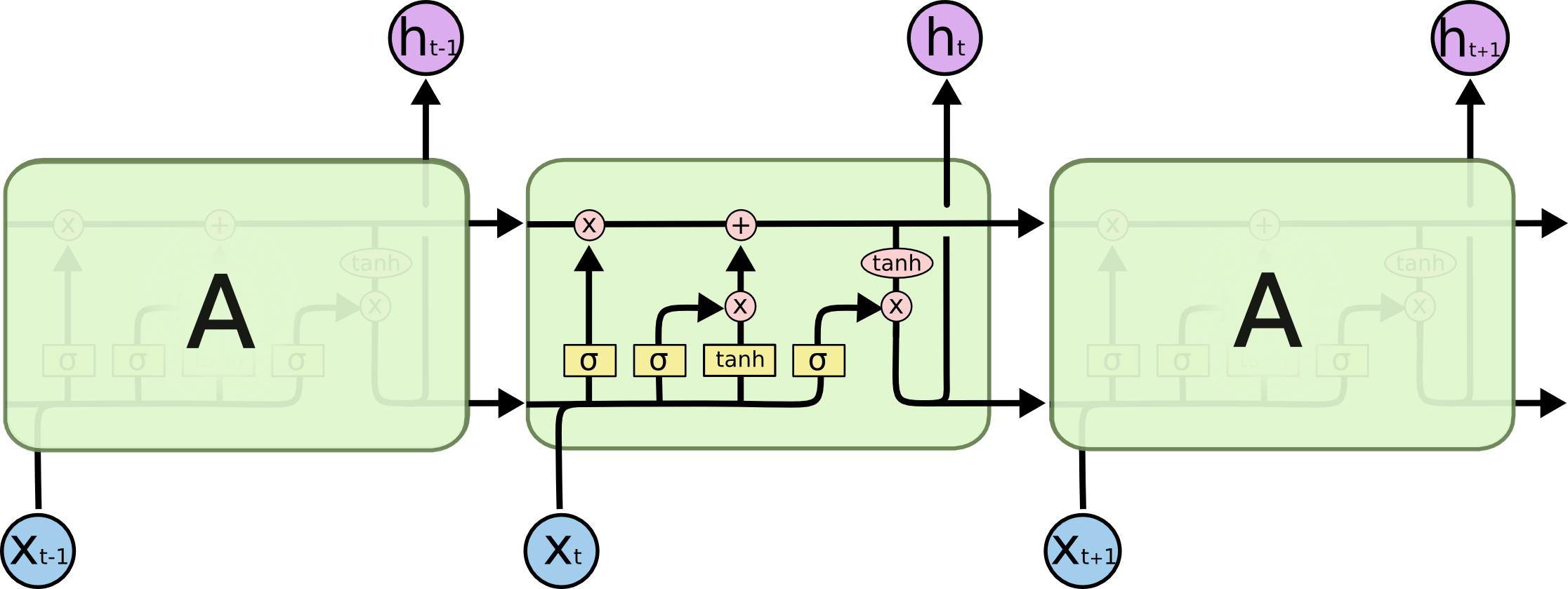
LSTM设计了一些权重(其他教程中常表述为“门”,我觉得搞复杂了,实际上就是权重)来权衡隐藏状态和输入,使得结果是有针对性地记住重要内容,而遗忘无关紧要的内容。上公式:
\[\begin{gather} f^{t} = \sigma(W^{f}x^{t} + U^{f}h^{t-1}) \\ i^{t} = \sigma(W^{i}x^{t} + U^{i}h^{t-1}) \\ o^{t} = \sigma(W^{o}x^{t} + U^{o}h^{t-1}) \\ \tilde{c^{t}} = tanh(W^{c}x^{t} + U^{c}h^{t-1}) \\ c^{t} = f^{t} \odot c^{t-1} + i^{t} \odot \tilde{c^{t}} \\ h_t = o^{t} \odot tanh(c^{t}) \end{gather}\]这堆公式乍一眼看上去很唬人,但实则很好理解。还是不变的思路,这一时刻的状态=这一时刻的输入+上一时刻的状态,不同的就是多了中间形态$c$。步骤如下:
- 公式先定义了三个权重(门)$f,i,o$;
- 然后权衡得到了中间态;
- 中间态同样需要权衡,于是分别乘了两个权重;
- 最后激活中间态再用掉最后一个权重,就得到了最终隐藏状态。
用伪代码可以表示为:
1
2
3
4
5
6
combined = cat((x, h_t))
f = sigmoid(gate(combined))
i = sigmoid(gate(combined))
o = sigmoid(gate(combined))
c = mul(c_t_1, f) + mul(tanh(gate(combined)), i)
h = mul(tanh(c), o)
聪明的你也许会问:为啥需要中间态啊,直接用权重不好吗,恭喜你发明了GRU,我把公式贴在下面,大家自行理解:
\[\begin{gather} r^{t} = \sigma(W^{r} \cdot [h^{t-1},x^{t}]) \\ z^{t} = \sigma(W^{z} \cdot [h^{t-1},x^{t}]) \\ \tilde{h^{t}} = tanh(W \cdot [r^{t} \odot h^{t-1},x^{t}]) \\ h_t = (1-z^{t}) \odot h^{t-1} + z^{t} \odot \tilde{h^{t}} \end{gather}\]以上就是原理介绍部分,下面我们进入代码实战。
基于AKShare+LSTM的股票市场预测
为了直观展示数据和模型,这里用jupyter notebook,打开notebook直接复制进去即可。
1.获取股票数据
使用akshare获取沪深300的个股基本面,作为我们的数据集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import akshare as ak
import pandas as pd
sh300 = ak.index_stock_cons("000300")
for i,code in enumerate(sh300["品种代码"].unique()):
stock_df_one = ak.stock_zh_a_hist(symbol=code, period="daily",
start_date="20180528", end_date="20190528",
adjust="qfq")
stock_df_one["品种代码"] = code
if i == 0:
stock_df = stock_df_one
else:
stock_df = pd.concat([stock_df, stock_df_one])
stock_df.drop_duplicates(inplace=True)
len(stock_df)
得到57190条数据。顺手保存一下:
1
stock_df.to_csv("stocks.csv", index=False)
2.预处理
数据存在缺失值,我们将缺少数据的那支股票直接剔除:
1
2
3
4
5
6
7
# 得到天数的众数,去除不符的股票
days = stock_df.groupby("品种代码").日期.count()
stock_df = stock_df[stock_df["品种代码"].isin(days.keys()[days == days.mode()[0]])]
stock_df.reset_index(drop=True, inplace=True)
# 所有股票的天数必须相同
assert len(stock_df) % len(stock_df["品种代码"].unique()) == 0
stock_df
获得48800 rows × 12 columns的dataframe。
接着打标签:采用后一天开收盘 - 今天开收盘,涨标记为 1,跌标记 0 。
1
2
3
4
5
6
7
8
9
10
11
day_num = len(stock_df["日期"].unique())
stock_num = len(stock_df["品种代码"].unique())
print("股票数量:"+str(stock_num)+'\n'+'天数:'+str(day_num))
all_data = []
for index, group in stock_df.groupby("品种代码"):
group["y"] = group["收盘"].shift(-1)-group["收盘"]
group["y"] = group["y"].apply(lambda x: 1 if x>=0 else 0) # 涨1跌0
group.drop(["品种代码","日期"],axis=1,inplace=True)
all_data.extend(group.values[:-1]) # 删掉最后没有标签的那一行
print(len(all_data))
归一化:
1
2
3
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
all_data = scaler.fit_transform(all_data)
切分训练、测试集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import numpy as np
all_x = np.array(all_data)[:,:-1]
train_x, test_x = [], []
for i in range(0, len(all_x), day_num-1):
train_x.append(all_x[i:i+int((day_num-1)*0.7)]) # 取前70%作为训练集
test_x.append(all_x[i+int((day_num-1)*0.7):i+day_num-1]) # 取后30%作为测试集
train_x = np.array(train_x)
test_x = np.array(test_x)
all_y = np.array(all_data)[:,-1]
train_y, test_y = [], []
for i in range(0, len(all_y), day_num-1):
train_y.append(all_y[i:i+int((day_num-1)*0.7)]) # 取前70%作为训练集
test_y.append(all_y[i+int((day_num-1)*0.7):i+day_num-1]) # 取后30%作为测试集
train_y = np.array(train_y)
test_y = np.array(test_y)
3.模型
定义LSTM的模型结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import torch
from torch import nn
from torch.autograd import Variable
class LSTM(nn.Module):
def __init__(self, input_size, output_size, num_classes=2, classification=False):
super(LSTM, self).__init__()
self.hidden_size = output_size
self.cell_size = output_size
self.tanh = nn.Tanh()
self.sigmoid = nn.Sigmoid()
self.gate = nn.Linear(input_size + output_size, output_size)
self.hidden = self.init_hidden()
self.cell = self.init_cell()
self.classification = classification
if self.classification:
self.output_dense = nn.Linear(output_size, num_classes)
def forward(self, x, h_t, c_t):
combined = torch.cat((x, h_t), 1)
f = self.sigmoid(self.gate(combined))
i = self.sigmoid(self.gate(combined))
o = self.sigmoid(self.gate(combined))
c = torch.add(torch.mul(c_t, f), torch.mul(self.tanh(self.gate(combined)), i))
h = torch.mul(self.tanh(c), o)
if self.classification:
output = self.output_dense(h)
else:
output = h
return output, h, c
def init_hidden(self):
return Variable(torch.zeros(1, self.hidden_size))
def init_cell(self):
return Variable(torch.zeros(1, self.cell_size))
定义超参数、准备数据集和初始化模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
num_epochs = 20
lr_init = 0.01
random_seed = 42
torch.manual_seed(random_seed)
input_size = len(train_x[0][0])
train_x = torch.Tensor(train_x).to(device)
day_num = train_x.shape[0]
LSTMmodel = LSTM(input_size=input_size, output_size=32, classification=True).to(device)
criterion = torch.nn.CrossEntropyLoss()
LSTMmodelOptimizer = torch.optim.Adam(LSTMmodel.parameters(), lr=lr_init)
训练:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
LSTMmodel.train(mode=True)
print("Training...")
for epoch in range(num_epochs):
total_loss = 0.0
preds_train = []
for stock in range(len(train_x)):
LSTMmodelOptimizer.zero_grad()
for x, label in zip(train_x[stock], train_y[stock]):
x = x.unsqueeze(0)
out, hidden, cell = LSTMmodel(x,LSTMmodel.hidden.to(device),LSTMmodel.cell.to(device))
label = torch.LongTensor([int(label)]).to(device)
loss = criterion(out, label)
loss.backward()
LSTMmodelOptimizer.step()
total_loss += loss.item()
print("Epoch: {}\tLoss: {}".format(epoch, total_loss / day_num), end="\n")
测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.metrics import accuracy_score
test_x = torch.FloatTensor(test_x).to(device)
day_num = train_x.shape[0]
labels_test = []
preds_test = []
LSTMmodel.eval()
with torch.set_grad_enabled(False):
for i in range(len(test_x)):
for x, label in zip(test_x[i], test_y[i]):
x = x.unsqueeze(0)
out, hidden, cell = LSTMmodel(x,LSTMmodel.hidden.to(device),LSTMmodel.cell.to(device))
labels_test.append(label)
_, out_binary = torch.max(out, 1)
preds_test.append(out_binary.cpu().tolist()[0])
print("LSTM accuracy_score: {}".format(accuracy_score(labels_test, preds_test)))
最后得到预测结果。我的结果是0.72,是不是太高了点?简直难以置信。
以上代码全部粘贴进notebook可以直接运行,并不需要额外数据。但这份代码存在许多问题,如:
- 没有验证集。
- 检验训练/测试的数据分布。
- 没有优雅地用
DataLoader等处理数据,也没有引入batch,导致x.unsqueeze(0)以及torch.LongTensor([int(label)])这种其丑无比的代码出现,且比较慢。
如果您对这些点进行了改进,欢迎评论留言或者私信我,我将会在本博客作者中加入您,万分感谢!